
Back to our Edge series. Sean Carroll says Bayes’s Theorem should be better known. He outlines the theorem in the familiar updating-prior-belief formula. But, as this modified classic article shows, this is not the most important facet of Bayesian theory.
Below we learn all probabilities fit into the schema 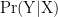
This post is modified version of one that was been restored after The Hacking. All original comments were lost.
Bayesian theory probably isn’t what you think. Most have the idea that it’s all about “prior beliefs” and “updating” probabilities, or perhaps a way of encapsulating “feelings” quantitatively. The real innovation is something much more profound. And really, when it comes down to it, Bayes’s theorem isn’t even necessary for Bayesian theory. Here’s why.
Any probability is denoted by the schematic equation
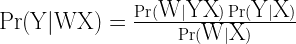
We start knowing or accepting the premise X, then later assume or learn W, and are able to calculate, or “update”, the probability of Y given this new information WX (read as “W and X are true or assumed true”). Bayes’s theorem is a way to compute 
Given X = “This machine must take one of states S1, S2, or S3”, we want the probability Y = “The machine is in state S1.” The deduced answer is 1/3. We then learn W = “The machine is malfunctioning and cannot take state S3”. The probability of Y given W and X is deduced as 1/2, as is trivial to see.
Now let’s find the result by applying Bayes’s theorem, the results of which must match. We know that 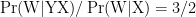


Most scientific, which is to say empirical, propositions start with the premise that they are contingent. This knowledge is usually left tacit; it rarely (or never) appears in equations. But it could: we could compute 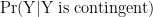
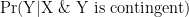
Of course, there are many instances in which Bayes facilitates. Without this tool we would be more than hard pressed to calculate some probabilities. But the point is the theorem can but doesn’t have to be invoked as a computational aide. The theorem is not the philosophy.
The real innovation in Bayesian philosophy, whether it is recognized or not, came with the idea that any uncertain proposition can and must be assigned a probability, not in how the probabilities are calculated. (This dictum is not always assiduously followed.) This is contrasted with frequentist theory which assigns probabilities to some unknown propositions while forbidding this assignment in others, and where the choice is ad hoc. Given premises, a Bayesian can and does put a probability on the truth of an hypothesis (which is a proposition), a frequentist cannot—at least not formally. Mistakes and misinterpretations made by users of frequentist theory are legion.
The problem with both philosophies is misdirection, the unreasonable fascination with questions nobody asks, which is to say, the peculiar preoccupation with parameters. About that, another time.
Discover more from William M. Briggs
Subscribe to get the latest posts sent to your email.
Pingback: Sampling Variability Is A Screwy, Misleading Concept | William M. Briggs
Pingback: The Bayesian Metaphor Can Do More Harm Than Good – William M. Briggs
You do realize that persistence with these outlooks will only delay the employment offer from the Department of Statistical Anomalies. yes? It may however increase your prospects if another Librarian opening should arise at the Library.
A cryptic reference by DAV, known only to devotees of the Library, the chief Librarian of which has an auspicious name.
Dr. Horace Worblehat?
Why haven’t the big forehead people conquered us by now?
Pingback: Sean Carroll’s “The Big Picture” Reviewed: Why “Poetic Naturalism” is an Oxymoron — Guest Post by Bob Kurland – William M. Briggs
Pingback: Against Moldbug’s Reservationist Epistemology: Reason Alone Is Not Reasonable – William M. Briggs
Pingback: Is Presuming Innocence A Bayesian Prior? – William M. Briggs
Pingback: There Is No Prior? What’s A Bayesian To Do? Relax, There’s No Model, Either – William M. Briggs
Pingback: Poor Richard Carrier Goes On The Offensive – William M. Briggs
Pingback: Yep, Probability Is Not As Simple As You Think – William M. Briggs
Pingback: Why Moldbug/Yarvin/Alexander’s Bayesian Rationality Fails – William M. Briggs
Pingback: There Is No Problem Of Old Evidence In Bayesian Probability – William M. Briggs
Pingback: How Not To Think Like A Bayesian Rationalist – William M. Briggs
Pingback: How Not To Think Like A Bayesian Rationalist