
We’re almost done. Only one more after this.
There are examples without number of the proper use of Bayes’s Theorem: the probability you have cancer given a positive test and prior information is a perennial favorite. You can look these up yourself.
But be cautious about the bizarre lingo, like “random variable”, “sample space”, “partition”, and other unnecessarily complicated words. “Random variable” means “proposition whose truth we haven’t ascertained”, “sample space” means “that which can happen” and so on. But too often these technical meanings are accompanied by mysticism. It is here the deadly sin of reification finds its purchase. Step lightly in your travels.
Let’s stick with the dice example, sick of it as we are (Heaven will be the place where I never hear about the probability of another dice throw). If we throw a die—assuming we do not know the full physics of the situation etc.—the probability a ‘6’ shows is 1/6 given the evidence about six-sided objects, etc. If we throw the same die again, what is the probability a second ‘6’ shows? We usually say it’s the same.
But why? Short answer is that we do so when we cannot (or will not) imagine any causal path between the first and second throws.
Let’s use Bayes’s theorem. Write 
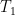
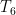
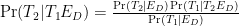
In this formula (which is written correctly), we know 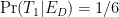
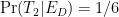
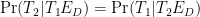
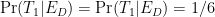
But there’s something bold in the way we wrote this formula. It assumes what we wanted to predict, and as such it’s circular. It’s strident to say
There is some wear and stress on the die from first to second throw. This is indisputable. Casinos routinely replace “old” dice to forestall or prevent any kind of deviation (of the observed relative frequencies from the probabilities deduced with respect to
Bayes as we just wrote it exposes the gambler’s fallacy: that because we saw many or few ‘6’s does not imply the chance of the next toss being a ‘6’ is different than the first. This is deduced because we left out, or ignored, how previous tosses could have influenced the current one. Again: we leave this information out of our premises. That is, we have (as we just wrote) the result of the previous toss in the list of premises, but
This is crucial to understand. It is we who change
Think: in every problem, there are always an infinite number or premises we reject.
If it’s difficult to think of what premises to use in a dice example, how perplexing is it in “real” problems, i.e. experiments on the human body or squirrel mating habits? It is unrealistic to ask somebody to quantify their uncertainty in matters which they barely understand. Yet it’s done and people rightly suspect the results (this is what makes Senn suspicious of Bayes). The solution would be to eschew quantification and rely more on description until such time we have sufficient understanding of the proper premises that quantification is possible. Yet science papers without numbers aren’t thought of as proper science papers.
Conclusion: bad uses of probability do not invalid the true meaning of probability.
Next—and last—time: the Trials of Infinity.
Discover more from William M. Briggs
Subscribe to get the latest posts sent to your email.
I’ve been thinking (with a lot less depth) about a post on another blog that asked if the analogy given there – that employed dice in this way – was good enough.
I felt it wasn’t as it contained the circular argument you’ve laid out here, but I was unable to frame my response as you’ve done.
The two points I’ve refrained from making are:
1) The example chosen in that case would have a certain reception given that blog’s audience – generally numerate and interested and, crucially, used to seeing examples that use dice to refer to probability and so “knowing” that the probability of a specific number turning up on each throw is 1/6
2) If you make an effort to discard preconceptions that a *specific* die imitates a platonic bleen, how can I possibly assign equal probability to the prospect that any one of the 6 sides will appear after a single throw?
I don’t even need to think about *why* a dice may not be fair – I don’t need to list wear and tear or manufacturing faults or cheating. In the absence of my worldly knowledge about dice, my evidence shows me with certainty that it’s *possible* for a 6 to appear when the die is cast. This is something I can’t say about the faces 1 – 5.
So I have to judge that the prospect of another 6 after an initial 6 appearing is > 1 /6
T_1 means “A ’6′ on the first throwâ€, and T_6 means “A ’6′ on the second throwâ€.
T_2, yes?
mrsean2k has a point. Why wouldn’t we update our estimate of a 6 appearing after the first throw? There doesn’t have to be a causal link between tosses to do so.
@DAV
You could use a different device, a sack with six pieces of paper, numbered 1, 2, 3, 4, 5, 6. You can now choose after the draw of one piece of paper, to either toss that piece away, or to put it back.
If you toss it, the next draw has to be from the numbers left. If you put it back, the piece has a change to turn up again.
The die behaves as if you put the piece of paper back in the sack. But it is clear that you could use a device that behaves as if the piece is tossed away.
Devices that depend on more complicated ways of tossing the paper or putting it back are also possible.
If you’re trying to avoid preconceptions, then the current throw doesn’t tell you anything at all about the next. Maybe the die contains a mechanism to ensure numbers are not repeated. Maybe it contains a mechanism to change the numbers shown on its sides mid-throw. Or maybe the laws of physics work that way.
The philosophy of probability is difficult, and so far as I know not fully resolved. This effort doesn’t strike me as being a final answer either – but I’m not qualified to say what is.
However, it does strike me that several different things are being conflated. There are at least three different senses in which you can talk about probabilities. There are mathematical models of the real world, there’s our subjective sensory perception of the real world, and there’s the real world itself, about which opinions differ.
The toy examples you read about in mathematics textbooks are generally about mathematical models. We define a model in which dice give perfect 1/6 probabilities. Events are asserted to follow the axioms and rules of probability theory, such as those developed by Kolmogorov. And then we insert into our model of events model observers, with limited knowledge, and we determine given the axioms and assumptions listed, how much they could rightly deduce.
Inside the model there are then true probabilities (the model of the physics) and subjective probabilities (the beliefs of the modeled observers), and only in the limit can the latter approach the former.
The model is then used in an attempt to understand the real world, and we real observers within it. It turns out, we observe, that the mathematical model of probability fits reality quite well, at least to the extent that our observations match what we would expect the modeled observers to see. But we don’t actually know if that’s how the real world really works. Is it an illusion? Is the universe deterministic, or random? Is the past fixed and the future not yet determined, or are both fixed, or could both be undetermined? What does it mean to speak of events that could have happened but didn’t? Might all alternatives happen simultaneously, in ‘parallel universes’, so the universe as a whole is deterministic but our individual single-timeline view of it appears random? I do not think we have any way, besides mathematical aesthetics, of telling.
Regarding William’s hopes for heaven, it was Einstein who said that God does not play dice.
But Hawking said not only does God play dice, he sometimes throws them where we cannot see them. I fear heaven may not be as congenial as you hope.
@nullius
I agree on general principles that you it’s preconceptions all the way down, but to be fair, the preconception I was specifically attempting to avoid was:
” If you make an effort to discard preconceptions that a *specific* die imitates a platonic bleen”
which I think is the uppermost preconception in the stack.
Lawks, me grammar.
I think it is the frequentist in me but I am having trouble understanding Pr(T1|T2Ed).
I think it is fascinating that Pr(T2|T1Ed) feels much more understandable.
Words like Priors and Posteriors create a sense of time, which I am sure is essential absent in the equations, but by removing that (incorrect?) sense of time, I feel a need to create a “phase space” (if that’s the right technical term for the Universe of possibilities) and that seems to instantly pull me into frequentist paradigm.
I think I understand Prof Briggs’ basic point – Bayes gives you what you presume, and only what you presume – but currently I’m not at a level to understand what I am presuming and Pr(T1|T2Ed) “feels” like it will have a multitude of ways to be explained.
I’m looking for a way for it to be explained, and am aware I’m falling into frequentism.
Prof Briggs, anyone else, do you have any other ways to explain what it “means”?
Sander van der Wal,
So, if the device has a bias toward 6, how would you ever discover it if you don’t use all of the information? Doesn’t that mean updating at every step?
I think I see what Briggs is up to but I’m curious why anyone would choose to throw away previous information.
mrsean2k,
Yes, I agree. But there are lots of ways you can change the model from the standard ‘1/6’ dice model. Specifics distract from the general point.
This is why it’s normally better to say explicitly that you’re talking about a mathematical model. In a model, you can say the probability is 1/6 and suspend disbelief. If you try to pretend this is about reality, and introduce alternative, more ‘realistic’ assumptions, you can easily get yourself in a paradoxical pickle.
“One of these days in your travels a guy is going to come up to you and show you a nice brand-new deck of cards on which the seal is not yet broken, and this guy is going to offer to bet you that he can make the Jack of Spades jump out of the deck and squirt cider in your ear. But, son, do not bet this man, for as sure as you are standing there, you are going to end up with an earful of cider.”
Damon Runyon.
chinahand,
Prior and posterior involve a sense of time, but not necessarily the time of the events occurring. They’re usually talking about the time before and after *you find out*. So if you see or are told about the second dice throw first, you can then ask what you know about the first dice throw.
It’s not about what’s already happened, it’s about what you know, and you can find out about events out of sequence. It’s only an accidental feature of a particular sort of scenario that you find out about events in the same order they occur.
@DAV
Keeping notes isn’t the problem. You need hypotheses about what kind of device it is, and test these hypotheses. The trouble with real dice is not that they might be unfair, the problem is that the casino might know the exact kind of unfairness of the dice, and you might not.
Sander van der Wal,
That’s not the point. Suppose it’s just a variable with 6 states. I don’t know have any information initially so get 1/6 for each state. I’ve now run one experiment and got state #6. How many experiments should I run before I start using the information based on the states I’ve seen so far and apply it to the probability of seeing state #6 on the next experiment?
It seems to me it should be after each experiment.
DAV,
Are you assuming that the probabilities of each outcome are the same at every step? Or that they follow a single simple rule?
If the outcome of each experiment might come from a completely different process, following different rules, what can one experiment tell you about any other?
Nullius,
Are you assuming that the probabilities of each outcome are the same at every step?
No. Since the probability is what I know, I learn something new each time. In my view the probability should change. In the Briggs example I would have said the probability of a 6 after the first should be 2/7. (I don’t feel like typing out how I got there).
f the outcome of each experiment might come from a completely different process
As in some switching dice or whatever this thing is? I don’t know. I would go under the assumption that isn’t happening or they all acted the same until there was someway to show otherwise.
I should point out that the 2/7 value arises because of how I computed it. In any case, though, I would expect the probability of a 6 would increase from 1/6 because I’ve seen more 6’s than anything else. If doing that after the first run bothers anyone I would have to ask them (assuming 6 continues to come up more often) when they would concede 6 is more likely than the other states.
The way Briggs arrived at his probability of a 6 at T2 leads me to think he will still get 1/6 a step 10,000 regardless of what he’s seen.
No, I didn’t mean to ask whether your estimate of the probability was the same after each experiment. I’m asking if you’re assuming that the ‘true’ probability is always the same.
Why would you assume that because you’ve seen more sixes than anything else so far, that this would continue to apply to future outcomes?
I’m asking if you’re assuming that the ‘true’ probability is always the same
Ummm …. the probability is my level of certainty. What would “true” probability mean?
Why would you assume that because you’ve seen more sixes than anything else so far, that this would continue to apply to future outcomes?
I don’t. I would be saying that given what I’ve seen, I would expect 6’s to be more prevalent.
OK, why would you think 6’s would be more prevalent in future, just because they’ve been more prevalent in the past?
Or are you saying you only think they’re more prevalent in the past, and your estimate for the next experiment is still 1/6?
If you stuck your hand in boiling water and felt pain would you then think the pain would be more likely the next time than you (obviously) previously thought? The evidence suggests it would be. And what if you did it twice with the similar result? How long would it take you to start exercising precautions?
The same with the 6-state whatever. The only difference is it doesn’t hurt as much. What am I to use except previous experience?
@DAV
You would have theories. You can think of a die that is fair, and a different one that would be loaded. You would throw the die enough times to satisfy yourself that it was not loaded. Or not loaded enough to worry you.
If you had never seen a die before, you might formulate the theory of dies being fair, based on their physical appearance. And if you had experience with humans trying to cheat each other, you might also formulate a theory about dice being loaded.
If the die was the first thing you would see in your life, who knows what would happen.
Yes, but with the pan of water I’m assuming a physical model in which the temperature next time will be roughly the same as it was last time. That’s what I was trying to get at – it depends what model you’re assuming the phenomenon follows.
If you use a model in which the probability of a 6 is always 1/6, then it doesn’t matter how many times it comes up 6 to start with, the probability next time is still 1/6. The long run was just a coincidence.
If you use a model in which the probability of a 6 is a fixed but initially unknown value, then each successive observation modifies your assessment.
If you observe so many 6’s from one source, but then get told the next observation will be coming from a different source, potentially following a different rule, your probability reverts to 1/6, because according to your model you don’t know anything about this new source.
There’s no difference in what you see. The difference is in what you assume about the causal connection between the observations. If you use a model in which they all have the same fixed probability that you are trying to estimate, then the mechanism that gives rise to that probability is a common cause for all the observations. When told that the next observation is from a different source, the causal link is broken. You are back to knowing nothing in advance about the next observation.
If some was to assert that *every* update was from a new source about which you knew nothing, then you might revert to 1/6 on every go. Or you might instead assume that the sources are themselves selected from a population with a fixed probability, and try to estimate it. Or you might assume something else.
As in the Damon Runyon example, in the context of an offered bet you might assume that the outcome will turn out to be whatever loses you your money, *whatever* prediction you make. Newcomb’s paradox works similarly. There’s nothing to stop the observation being causally dependent on your estimate.
The point is, what you can deduce depends on what mathematical model of the probabilities you use to model the true situation. And the mathematics puts no limits on that. Some models turn out to work better in practice, but that’s an apparent feature of the laws of physics, not inherent to the Bayesian mathematics. “The most incomprehensible thing about the universe is that it is comprehensible.” Physics shows these strong regularities and simple relationships, but we don’t know why. Mathematically, so far as we know, it doesn’t have to.
From a Bayesian point of view, it is essentially the problem of priors. Bayes can tell you, given a probability model, how to modify your prior to get a posterior, but it cannot tell you what your priors or probability model should be. When we explicitly incorporate our probability model of the situation into our formulation, we find we need a prior for the model, too. Trying to do everything within a Bayesian framework results in infinite regress.
Having briefly skimmed Senn’s paper, most of the examples he discusses seem related to the problem of priors, too. I think he’s saying that ‘Bayesians’ sometimes forget, and imagine their conclusions are founded *entirely* on rigorous deduction from the evidence. I don’t know, but it sounds psychologically plausible. Statisticians are only human, after all.
Pingback: Jumping The Infinity Shark: An Answer To Senn; Part Last | William M. Briggs
Nullius,
Suppose you were 5 years old and suppose the water was just really hot and not boiling and you didn’t know about temperature, etc.? I’ll bet anything you would cringe the next time you went to put your hand in a pot of water and you hadn’t the first time. If so then your certainty in experiencing unpleasantness has been increased. You don’t need a theory — just a previous observation. It’s human nature to guess why but first comes the observation and the altered certainty.
Am I supposed to assume a 5 year old is being a logically rigorous Bayesian about this? :-)
Whether children know about hot water or not, they do know about the persistence of properties through time. (Whether learned or instinctive.) They are assuming a particular model of the world, dividing it into things that can hurt and things that don’t. Given this model it makes sense to update your beliefs about pots of water on finding that it’s hot. But the deduction depends on the model.
If the world was such that properties were not persistent, then a child would learn that if it hurt last time, it’s probably safe this time. They would operate with a different model. For example, if they grew up in an environment where static electricity built up on everything, they’d learn to be wary the first time they touched something, but be relaxed about picking it up immediately after. The first time they came across hot water, they’d probably assume it worked the same. The models that work depend on physics.
But it’s still a model, and if you’re doing mathematics, you still have to list it in the assumptions/conditions. If you start with a different model, you get a different answer.
Nullius,
you continue to state things like ‘true’ probability and population with a fixed probability.
The basic difference between Bayesians and frequentists is centered on what probability means. You obviously adhere to frequentist meaning.
In Bayesian terms the above comes across as ‘true’ certainty and population with a fixed certainty.
One doesn’t estimate one’s certainty anymore than one estimates how good the current meal tastes or estimates how nice the sunset is. One can change one’s certainty just as one can change tastes but at any given time it is what it is.
We apparently are talking about two different things.
No, Bayesians talk about true probabilities, too.
I think William’s interpretation there is a little odd, but I didn’t see any point in arguing with it. Strongly held opinions tend to result in unresolvable conflicts. And I’ve argued often enough about Bayesian probability versus Bayesian belief to no longer be interested in doing it just for the fun of it. Although if someone seems interested I don’t mind explaining.
I gave the rough outline at 10:06 yesterday.
Yes, we’re talking about two different things.