
Still with me? Hope so, because we’re only on the second page of Senn’s article (but don’t fret; we’ll be skipping most of it).
Review: in logical-probability Bayes (as in all Aristotelian logic), we begin with a list of premises (data, observations, evidence, or other synonymous term) and a proposition which is hoped to be related to the premises; from the premises we deduce the probability the proposition is true. Not all premises are sufficient to guarantee a numerical value, nor any value, nor any precise number: the probability could be stated merely in words, nonexistent, an interval, or a precise number.
Senn writes “we let 

As before, I already disagree. There just is no such thing as unconditional probability, or probability without respect to any evidence, thus it never makes sense to write “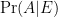
Example: A = “A ‘6’ shows” and E = “We have a Martian breen, etc.” (see the previous part for an explanation). But it makes no sense to ask, “What is the probability a ‘6’ appears” without reference to something—whether it be a breen, a die, or something else.
Failure to recognize this creates another stumbling block in understanding probability. Probability is usually introduced as unconditional, and the complexity of conditioning follows some time later: but this is a mistake. There just is no such thing as unconditional probability. Just as there is no unconditional truth (of a proposition, we always at least refer to our intuition or faith if not a list of premises.)
Of course, inside a given problem, once we have E in hand, and it’s agreed to by all and always understood to be there, and for the simple ease of notation, there is no harm in writing
Don’t think this is a big deal? Oh, boy, is it ever, as we’ll see.
Senn introduces 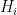

Senn then writes (with my change in notation) “We suppose that we have some evidence E . If we are Bayesians we can assign a probability to any hypothesis 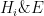
Subjective Bayesians would agree: logical probability Bayesians do not. Subjective Bayesians are as free with numerical probabilities as politicians are with other people’s money. Subjectivists “feel” probability is a matter of emotion because they fail to write down the conditioning premises. They may arrive at a number (and bet using it: subjectivists are inveterate gamblers; at least in theory), but this does not mean the numbers they produce have any bearing on the probabilities unless it can be demonstrated their (unwritten) premises imply these (and no other) numerical values. There is much more to the errors subjectivists make, but given that they usually only make them in theory and not in many problems, where they usually agree with LPBs, we’ll let these go until another day.
LPBs are more Socratic and admit their ignorance. The original series proves the LBPs are right: we can not always discover a probability, and so we can not always discover a numerical value for a probability. We can still manipulate the symbols until we get the form of an answer, but that doesn’t make the answer right. I believe Senn would agree with that.
Thus we can always write Bayes’s theorem, which Senn does:
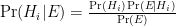
Spot the trouble? What could it possibly mean to say 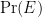
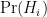
We’re in just as much trouble with
The problem does not lie in Bayes’s theorem, which nobody disputes (how could they?), but in the way it is written and what the symbols mean. Senn is right that Subjective Bayesians can (and do) say anything, but that doesn’t mean what they say has any bearing on reality (I’ll let you provide the politician comparison).
About that, more next time.
Discover more from William M. Briggs
Subscribe to get the latest posts sent to your email.
In an Euler diagram of all possible outcomes of a given experiment, a theory is a subset of these outcomes. Different theories are different subsets.
If a measurement Ex is not in subset Hi, Hi is false. And all the other theories Hk that contain Ex are false too.
If a measurement Ey is in the subset Hi, then the theory Hi might be true. And all the other subsets Hk that contain Ey might be true too.
The joint probabilities of H and E are statistically independent: Pr(Hi | Ey).Pr(Ey) = Pr(Hi).Pr(Ey), so the conditional probabilities are Pr(Hi | Ey) = Pr(Hi).
This should be obvious: different theories can predict the same measurement. Once a measurement is predicted by some theory, it is not taken. Other theories must predict that measurement to, to be true.
Sander,
Good grief is that complicated. You lost me with subset.
How about this? Assuming H_i is true, the probability of E is 0. We subsequently observe E. Therefore, H_i is false.
Or assuming H_i is true, the probability of E is tiny (and as tiny as you like but not 0). We subsequently observe E. Therefore, H_i might still be true.
Finis.
“Senn is right that Subjective Bayesians can (and do) say anything, but that doesn’t mean what they say has any bearing on reality (I’ll let you provide the politician comparison).”
Hmmm? Senn states the following in his article. He seems to say otherwise.
JH,
Hmm. You’ll have to show me just where you think he says otherwise. Seems to me he agrees.
Pingback: An Ensemble Of Models Is Completely Meaningful, Statistically | William M. Briggs
Pingback: This Week in Reaction | The Reactivity Place